

PUBLICATIONS

Deep Convolutional Neural Networks and Data Augmentation for Acoustic Event Recognition
We propose a novel method for Acoustic Event Recognition. In order to incorporate the long-time frequency structure of acoustic events produced by a wide variety of sources, we introduce a CNN with a large input field which enables to train audio event recognition end-to-end. In order to prevent over-fitting and to take full advantage of the modeling capabilities of our network, we further propose a novel data augmentation method to introduce data variation. Experimental results show that our CNN significantly outperforms state of the art methods. Interspeech 2016

Automatic Pronunciation Generation by Utilizing a Semi-supervised Deep Neural Networks
We propose a data-driven pronunciation estimation and acoustic modeling method which only takes the orthographic transcription to jointly estimate a set of sub-word units and a reliable dictionary. Experimental results show that the proposed method which is based on semi-supervised training of a deep neural network largely outperforms phoneme based continuous speech recognition on the TIMIT dataset. Interspeech 2016

Noise reduction combining microphone and piezoelectric device
We propose a novel sound separation method that utilizes both a microphone and a piezoelectric device attached to the body of the instrument. The signal from the attached device has a different spectrum from the sound heard by the audience but has the same frequency components as the instrumental sound with much less interferences. Our idea is to use the device signal as a modifier of the sound focusing filter applied to the microphone sound at the listening position. ICA 2007
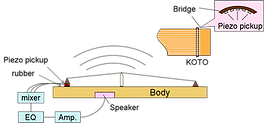
Electric KOTO by vibrating body
The Japanese string instrument called KOTO is revamped to play with high-volume instruments such as the electric bass and drams. In order to maintain a natural timber and sound field produced by KOTO while preventing interference from high-volume instruments, the vibration of the instruments is directly amplified. ICMC 2007
Multi-scale Multi-band DenseNets for Audio Source Separation
We propose a novel network architecture, MMDenseNet for the problem of audio source separation. To deal with the specific problem of audio source separation, an up-sampling layer, block skip connection and band-dedicated dense blocks are incorporated on top of DenseNet. The proposed approach takes advantage of long contextual information and outperforms state-of-the-art results on SiSEC 2016 competition by a large margin in terms of signal-to-distortion ratio. Moreover, the proposed architecture requires significantly fewer parameters and considerably less training time compared with other methods. WASPAA 2017
